This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
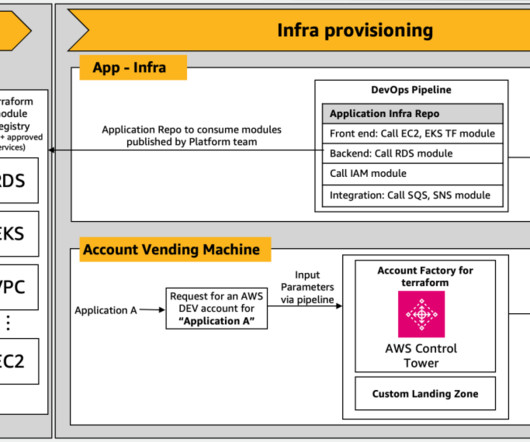
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. Run the script init-script.bash : chmod u+x init-script.bash./init-script.bash
You might have a carefully crafted questionnaire or script for your after-call survey. It offers your call center a well-documented view of response rates, survey answers, and timing information. Sample After-Call Survey Script. Use this handy sample script as a guide! Introduce surveys by using the customer’s name.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
Amazon Bedrock empowers teams to generate Terraform and CloudFormation scripts that are custom fitted to organizational needs while seamlessly integrating compliance and security best practices. Traditionally, cloud engineers learning IaC would manually sift through documentation and best practices to write compliant IaC scripts.
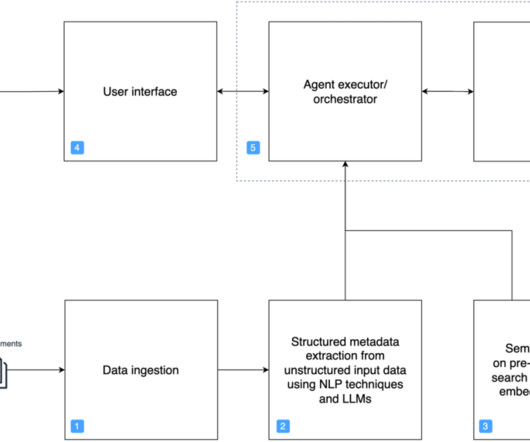
Broadly speaking, a retriever is a module that takes a query as input and outputs relevant documents from one or more knowledge sources relevant to that query. Document ingestion In a RAG architecture, documents are often stored in a vector store. You must use the same embedding model at ingestion time and at search time.
While on site, they use Connectivity Guru to run site scans, confirm signal coverage, document the setup (“birth certificate”), optimize hardware placement and use visual aids to drive upsales. TechSee empowers you to flip the script—with visual intelligence that makes WiFi problems visible, solvable, and even profitable.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
Average Handle Time (AHT) gives an accurate, real-time measurement of the usual amount of time it takes to handle an interaction from start to finish, from the initiation of the call to the time your organization’s call center agents are spending on the phone with individual callers and handling any follow-up tasks, such as documentation.
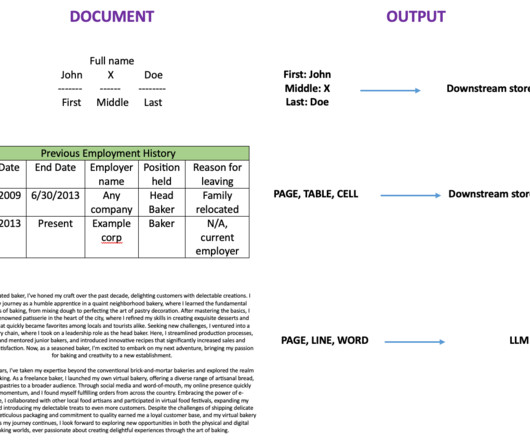
Data classification, extraction, and analysis can be challenging for organizations that deal with volumes of documents. Traditional document processing solutions are manual, expensive, error prone, and difficult to scale. FMs are transforming the way you can solve traditionally complex document processing workloads.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. script provided with the CRAG benchmark for accuracy evaluations.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
Organizations across industries such as retail, banking, finance, healthcare, manufacturing, and lending often have to deal with vast amounts of unstructured text documents coming from various sources, such as news, blogs, product reviews, customer support channels, and social media. Extract and analyze data from documents.
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. Who are the data stewards for my proprietary database sources?
BERT is pre-trained on masking random words in a sentence; in contrast, during Pegasus’s pre-training, sentences are masked from an input document. The model then generates the missing sentences as a single output sequence using all the unmasked sentences as context, creating an executive summary of the document as a result.
Call centers follow strict compliance protocols, including: PCI DSS certification for payment security HIPAA compliance for health-related policies Secure call recording and data storage Key Features of an Insurance-Focused Call Center Customized scripts for different policy types (auto, life, health, etc.) A: Not likely.
Call centers play a pivotal role in optimizing client intake by providing: 24/7 availability to answer client inquiries Professional and courteous communication Accurate data collection and case documentation Timely follow-ups and appointment scheduling How Call Centers Improve Client Intake for Law Firms 1.
Encourage agents to cheer up callers with more flexible scripting. “A 2014 survey suggested that 69% of customers feel that their call center experience improves when the customer service agent doesn’t sound as though they are reading from a script. Minimise language barriers with better hires.
Your task is to understand a system that takes in a list of documents, and based on that, answers a question by providing citations for the documents that it referred the answer from. Our dataset includes Q&A pairs with reference documents regarding AWS services. The following table shows an example.
We discovered that after placing an order, the insurance company agent would tell the customers, “Your policy documents should be with you within five days.” We had the agents say instead, “Your policy documents will be with you within five days.” ” It was the word “should.”
Not only will this solution document your product or services as a whole, but it also gives your business the opportunity to analyze, gather and address common customer concerns. This means cutting out the scripts and taking on a positive and natural tone when talking. Respond to (every) negative and positive feedback.
Training documentation needs to be updated regularly, and on-going training is important for improving efficiency. Bill Dettering is the CEO and Founder of Zingtree , a SaaS solution for building interactive decision trees and agent scripts for contact centers (and many other industries). Bill Dettering. Jeff Greenfield.
Features include: Customized scripts Bilingual agents Call recording and analytics Secure CRM and calendar integration How After-Hours Services Work A good after-hours call center becomes an extension of your team. Here’s how they support you: Answer Calls with Customized Scripts: Agents follow your tone and brand voice.
Accelerate research and analysis – Instead of manually searching through SharePoint documents, users can use Amazon Q to quickly find relevant information, summaries, and insights to support their research and decision-making. The site content space also provides access to add lists, pages, document libraries, and more.
Can you provide documentation of compliance certifications? Professional call centers use customized scripts and tone guidelines to align with your brand voice. A: It depends on customization needs, but most setups can be completed in 24 weeks, including script development and training. How often do you perform security audits?
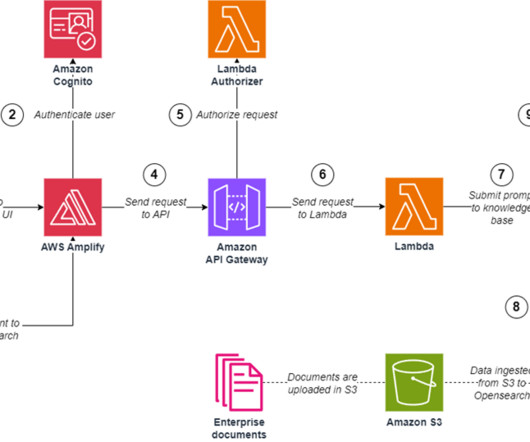
installed The AWS Amplify CLI set up Model access to the following models in Amazon Bedrock: Titan Embeddings G1 – Text and Claude Instant Upload documents and create a knowledge base In this section, we create a knowledge base in Amazon Bedrock. Upload the following documents in the S3 bucket: The Overview of Amazon Web Services whitepaper.
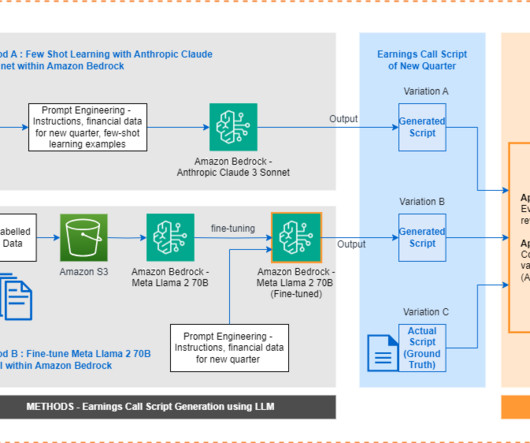
Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time. On the other hand, generative artificial intelligence (AI) models can learn these templates and produce coherent scripts when fed with quarterly financial data.
That said, millennials will absolutely turn to social media and peer-to-peer sharing to both document and absorb learnings. This group is also flipping the script when it comes to the preferred communication channel. They are literally changing the rules of customer service on the fly. Yes, really. Live messaging is where it’s at.
OCR has been widely used in various scenarios, such as document electronization and identity authentication. Because OCR can greatly reduce the manual effort to register key information and serve as an entry step for understanding large volumes of documents, an accurate OCR system plays a crucial role in the era of digital transformation.
To learn more about the SageMaker model parallel library, refer to SageMaker model parallelism library v2 documentation. With these updates to SMP’s APIs, you can now realize the performance benefits of SageMaker and the SMP library without overhauling your existing PyTorch FSDP training scripts.
Your Amazon Bedrock-powered insurance agent can assist human agents by creating new claims, sending pending document reminders for open claims, gathering claims evidence, and searching for information across existing claims and customer knowledge repositories. Send a pending documents reminder to the policy holder of claim 2s34w-8x.
In addition to HIPAA compliance, training should also cover emergency protocols, medical terminology , and documentation best practices. One of the ways of establishing clear protocols is to provide standardized scripts that can help agents assess the nature of each call accurately.
While sticking to set scripts can be helpful, being genuinely concerned with solving customer concerns helps customers feel valued. We have a very in-depth training process to work with customers and many documents outlining common questions and issues. They use canned, scripted responses that lack sincerity. HealthMarkets.
wiki, informational web sites, self-service help pages, internal documentation, etc.) The intended meaning of both query and document can be lost because the search is reduced to matching component keywords and terms. Create test indexes, and load some sample documents. Create and start OpenSearch using the Quickstart script.
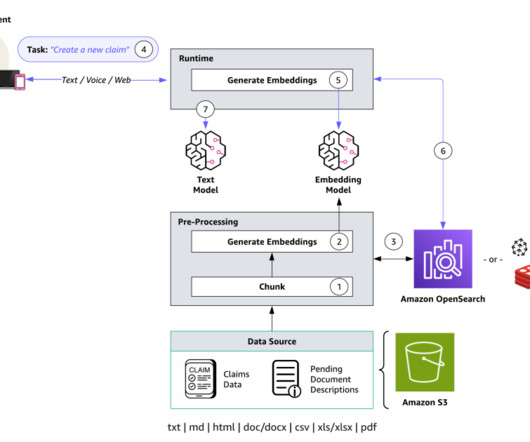
An S3 bucket where your documents are stored in a supported format (.txt,md,html,doc/docx,csv,xls/.xlsx,pdf). While running deploy.sh, if you provide a bucket name as an argument to the script, it will create a deployment bucket with the specified name. After the script is complete, note the S3 URL of the main-template-out.yml.
Scripts are tailored to match the legal or medical practices tone, procedures, and regulatory needs. A: Ask for compliance documentation, security certifications, and whether they are willing to sign a BAA. Inbound and Outbound Call Handling All calls are monitored and recorded securely.
CRM and ticketing systems Call routing platforms Knowledge bases and internal documentation Troubleshooting procedures 4. Develop a Standardized Training Curriculum Create a comprehensive, easy-to-follow training manual that includes scripts, FAQs, escalation protocols, and examples. healthcare, finance) 5.
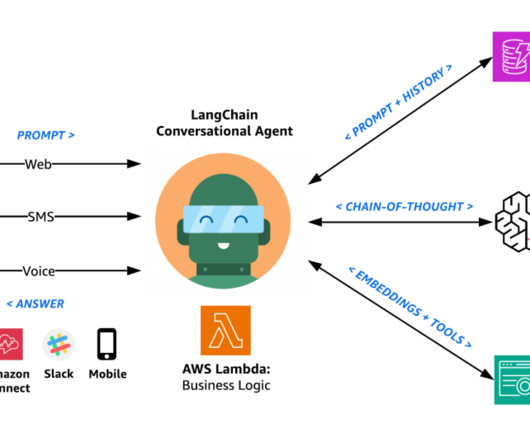
Lambda instruments the financial services agent logic as a LangChain conversational agent that can access customer-specific data stored on DynamoDB, curate opinionated responses using your documents and webpages indexed by Amazon Kendra, and provide general knowledge answers through the FM on Amazon Bedrock.
With your Python environment activated, run the following command: cdk synth Run the following command to deploy the AWS CDK: cdk deploy Run the following command to run the post-deployment script: python scripts/post_deployment_script.py CD into the scripts directory in the repository. script located in the GitHub repository.
When a Neuron SDK is released, you’ll now be notified of the support for Neuron DLAMIs and Neuron DLCs in the Neuron SDK release notes, with a link to the AWS documentation containing the DLAMI and DLC release notes. You also need the ML job scripts ready with a command to invoke them. Starting with the AWS Neuron 2.18
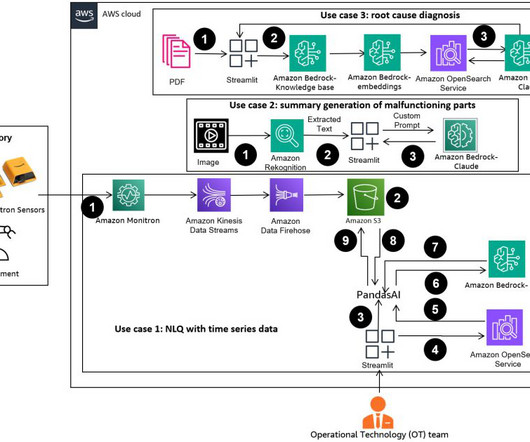
However, complex NLQs, such as time series data processing, multi-level aggregation, and pivot or joint table operations, may yield inconsistent Python script accuracy with a zero-shot prompt. Upload documents from the data folder assetpartdoc in the GitHub repository to the S3 bucket listed in the CloudFormation stack outputs.
For example, a use case that’s been moved from the QA stage to pre-production could be rejected and sent back to the development stage for rework because of missing documentation related to meeting certain regulatory controls. These stages are applicable to both use case and model stages. To get started, set-up a name for your experiment.
An effective call center script balances consistent service quality with personalized customer interactions. The script should serve as a guide rather than a rigid framework. While customer service scripts are incredibly useful and beneficial, they can also be challenging to create. Understand customer needs and expectations.
Dynamic Scripting: Crafting Personalized Conversations with Call Center Software In the contemporary business world, focusing on customers’ requirements and delivering a personalized experience is essential. Rather than sticking to a fixed script, it can change on the spot depending on what the customer is saying or doing.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content