This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
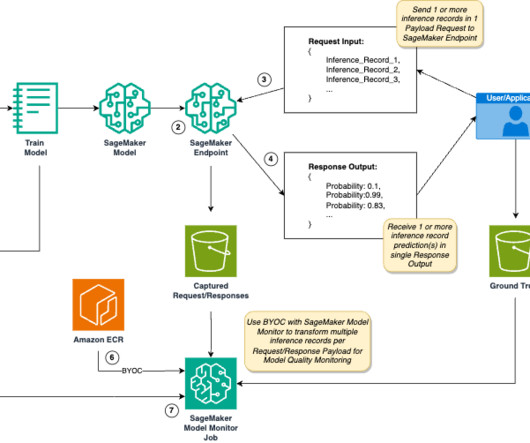
Examples include financial systems processing transaction data streams, recommendation engines processing user activity data, and computer vision models processing video frames. A preprocessor script is a capability of SageMaker Model Monitor to preprocess SageMaker endpoint data capture before creating metrics for model quality.
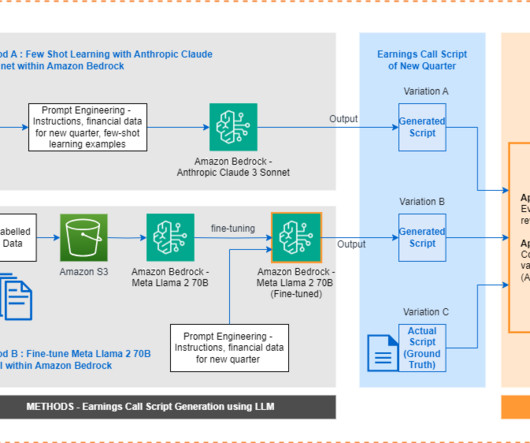
Investors and analysts closely watch key metrics like revenue growth, earnings per share, margins, cash flow, and projections to assess performance against peers and industry trends. Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time.
Rather than relying on static scripts, Sophie autonomously decides how to engage. Check out how Sophie AI’s cognitive engine orchestrates smart interactions using a multi-layered approach to AI reasoning. Visual troubleshooting? Step-by-step voice support? Chat-based visual guidance? ” Curious how it works?
Metrics, Measure, and Monitor – Make sure your metrics and associated goals are clear and concise while aligning with efficiency and effectiveness. Make each metric public and ensure everyone knows why that metric is measured. Interactive agent scripts from Zingtree solve this problem. Bill Dettering.
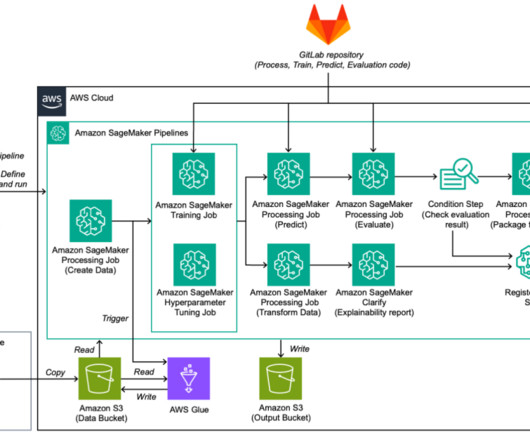
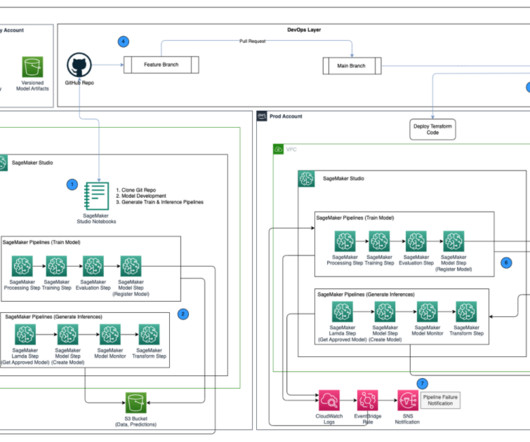
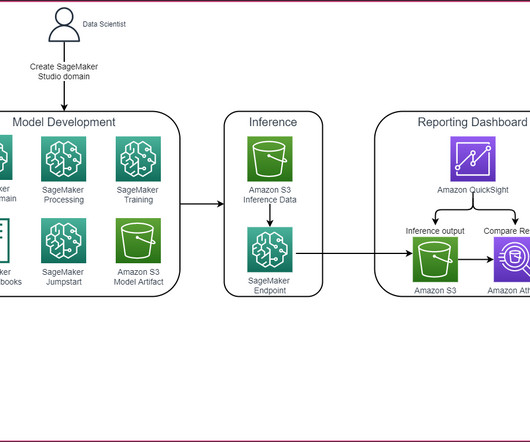
The DS uses SageMaker Training jobs to generate metrics captured by , selects a candidate model, and registers the model version inside the shared model group in their local model registry. Optionally, this model group can also be shared with their test and production accounts if local account access to model versions is needed.
Workforce Management 2025 Call Center Productivity Guide: Must-Have Metrics and Key Success Strategies Share Achieving maximum call center productivity is anything but simple. Revenue per Agent: This metric measures the revenue generated by each agent. For many leaders, it might often feel like a high-wire act.
For automatic model evaluation jobs, you can either use built-in datasets across three predefined metrics (accuracy, robustness, toxicity) or bring your own datasets. For early detection, implement custom testing scripts that run toxicity evaluations on new data and model outputs continuously.
How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics? Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics. script provided with the CRAG benchmark for accuracy evaluations. Each provisioned node was r7g.4xlarge,
We also included a data exploration script to analyze the length of input and output tokens. For demonstration purposes, we select 3,000 samples and split them into train, validation, and test sets. You need to run the Load and prepare the dataset section of the medusa_1_train.ipynb to prepare the dataset for fine-tuning.
This requirement translates into time and effort investment of trained personnel, who could be support engineers or other technical staff, to review tens of thousands of support cases to arrive at an even distribution of 3,000 per category. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
Now more than ever, organizations need to actively manage the Average-Speed-of-Answer (ASA) metric. Older citizens, the unhealthy, and those in low-income areas have always been targets for social engineering. Despite the pandemic, customers have retained the expectation that if they call you, you’ll be there for them.
To address the problems associated with complex searches, this post describes in detail how you can achieve a search engine that is capable of searching for complex images by integrating Amazon Kendra and Amazon Rekognition. A Python script is used to aid in the process of uploading the datasets and generating the manifest file.
In February 2022, Amazon Web Services added support for NVIDIA GPU metrics in Amazon CloudWatch , making it possible to push metrics from the Amazon CloudWatch Agent to Amazon CloudWatch and monitor your code for optimal GPU utilization. You can add or remove any metrics as needed. Then we explore two architectures.
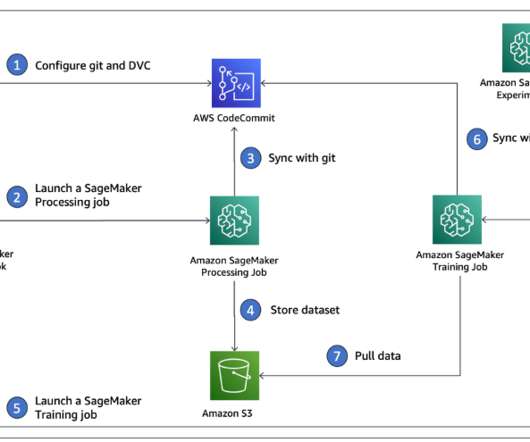
This enables data scientists to quickly build and iterate on ML models, and empowers ML engineers to run through continuous integration and continuous delivery (CI/CD) ML pipelines faster, decreasing time to production for models. You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices.
PrestoDB is an open source SQL query engine that is designed for fast analytic queries against data of any size from multiple sources. We use a preprocessing script to connect and query data from a PrestoDB instance using the user-specified SQL query in the config file. For more information on processing jobs, see Process data.
Evaluating a RAG solution Contrary to traditional machine learning (ML) models, for which evaluation metrics are well defined and straightforward to compute, evaluating a RAG framework is still an open problem. Mean Reciprocal Rank (MRR) – This metric considers the ranking of the retrieved documents.
However, training or fine-tuning these large models for a custom use case requires a large amount of data and compute power, which adds to the overall engineering complexity of the ML stack. Most of the details will be abstracted by the automation scripts that we use to run the Llama2 example. Cluster with p4de.24xlarge
Amazon Q Business only provides metric information that you can use to monitor your data source sync jobs. We recommend running similar scripts only on your own data sources after consulting with the team who manages them, or be sure to follow the terms of service for the sources that youre trying to fetch data from.
Scripts are an essential component of every contact center. The correct amount of data and accurate information delivery can yield impressive scripting capabilities. To provide a better customer experience (CX), dynamic agent scripting is required. Table of Contents show What is call center Dynamic Agent Scripting?
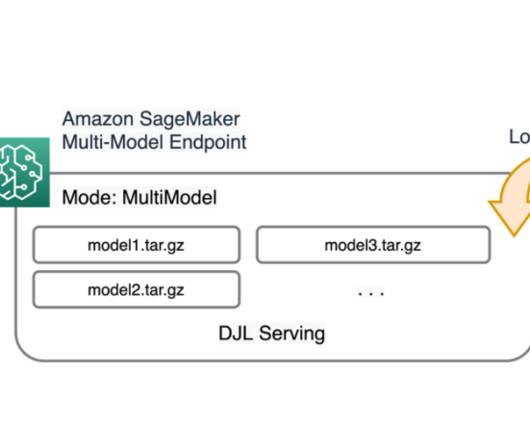
Integration with backend engines – Model servers have integrations with backend frameworks like DeepSpeed and FasterTransformer to partition large models and run highly optimized inference. Multi-engine support – DJL Serving can simultaneously host models using different frameworks (such as PyTorch and TensorFlow).
This post is co-authored by Anatoly Khomenko, Machine Learning Engineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com. The system is developed by a team of dedicated applied machine learning (ML) scientists, ML engineers, and subject matter experts in collaboration between AWS and Talent.com.
Reusable scaling scripts for rapid experimentation – HyperPod offers a set of scalable and reusable scripts that simplify the process of launching multiple training runs. The Observability section of this post goes into more detail on which metrics are exported and what the dashboards look like in Amazon Managaed Grafana.
Wipro further accelerated their ML model journey by implementing Wipro’s code accelerators and snippets to expedite feature engineering, model training, model deployment, and pipeline creation. Query training results: This step calls the Lambda function to fetch the metrics of the completed training job from the earlier model training step.
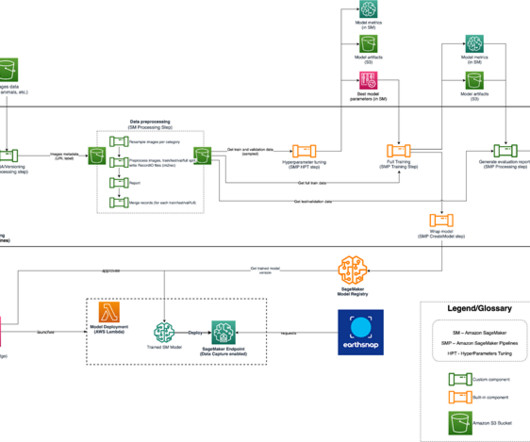
This post explains how Provectus and Earth.com were able to enhance the AI-powered image recognition capabilities of EarthSnap, reduce engineering heavy lifting, and minimize administrative costs by implementing end-to-end ML pipelines, delivered as part of a managed MLOps platform and managed AI services.
bin/bash # Set the prompt and model versions directly in the command deepspeed /root/LLaVA/llava/train/train_mem.py --deepspeed /root/LLaVA/scripts/zero2.json It sets up a SageMaker training job to run the custom training script from LLaVA. He has over a decade experience in the FinTech industry as software engineer.
Youre dealing with metrics and KPIs, sure, but also human emotions, tech stacks, and rapidly evolving customer expectations. Monitoring call center performance metrics is crucial for ensuring smooth customer interactions and motivated agents. Ensuring compliance with scripts and regulatory guidelines. Flip the script.
Youre dealing with metrics and KPIs, sure, but also human emotions, tech stacks, and rapidly evolving customer expectations. Monitoring call center performance metrics is crucial for ensuring smooth customer interactions and motivated agents. Ensuring compliance with scripts and regulatory guidelines. Flip the script.
We can follow a simple three-step process to convert an experiment to a fully automated MLOps pipeline: Convert existing preprocessing, training, and evaluation code to command line scripts. Use the scripts created in step one as part of the processing and training steps. Integrate the pipeline into your CI/CD workflow.
Training script Before starting with model training, we need to make changes to the training script to make it XLA compliant. We followed the instructions provided in the Neuron PyTorch MLP training tutorial to add XLA-specific constructs in our training scripts. These code changes are straightforward to implement.
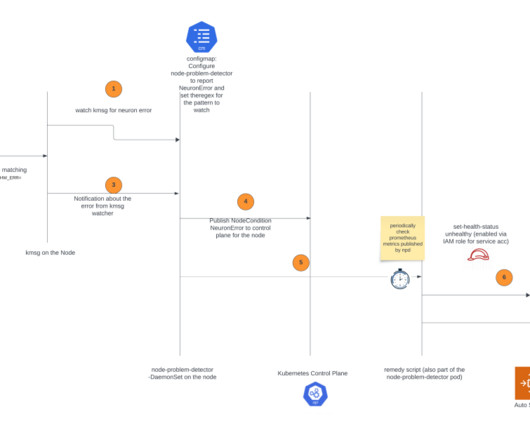
The node recovery agent is a separate component that periodically checks the Prometheus metrics exposed by the node problem detector. Additionally, the node recovery agent will publish Amazon CloudWatch metrics for users to monitor and alert on these events. You can see the CloudWatch NeuronHasError_DMA_ERROR metric has the value 1.
As machine learning (ML) models have improved, data scientists, ML engineers and researchers have shifted more of their attention to defining and bettering data quality. The PyTorch estimator from the sagemaker.pytorch package allows us to run our own training script in a managed PyTorch container.
Solution overview In this section, we present a generic architecture that is similar to the one we use for our own workloads, which allows elastic deployment of models using efficient auto scaling based on custom metrics. The reverse proxy collects metrics about calls to the service and exposes them via a standard metrics API to Prometheus.
For hyperparameter tuning, a hyperparameter optimization (HPO) job can be initiated, selecting the best model based on the objective metric. Evaluate – A PySpark processing job evaluates the model using a custom Spark script. This decision is based on a condition metric defined in the configuration file.
Before you can write scripts that use the Amazon Bedrock API, you need to install the appropriate version of the AWS SDK in your environment. For Python scripts, you can use the AWS SDK for Python (Boto3). For more information, refer to Prompt Engineering Guidelines. exclusive) to 10.0 Parse and decode the response.
The concepts illustrated in this post can be applied to applications that use PLM features, such as recommendation systems, sentiment analysis, and search engines. The performance of the architecture is typically measured using metrics such as validation loss. training.py ).
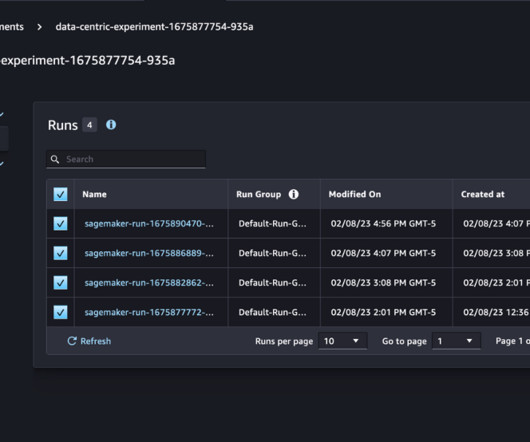
Data scientists often work towards understanding the effects of various data preprocessing and feature engineering strategies in combination with different model architectures and hyperparameters. In each individual experiment, we track input and output artifacts, code, and metrics using SageMaker Experiments. SageMaker Experiments.
Under Advanced Project Options , for Definition , select Pipeline script from SCM. For Script Path , enter Jenkinsfile. upload_file("pipelines/train/scripts/raw_preprocess.py","mammography-severity-model/scripts/raw_preprocess.py") s3_client.Bucket(default_bucket).upload_file("pipelines/train/scripts/evaluate_model.py","mammography-severity-model/scripts/evaluate_model.py")
Focus on search engine optimization (SEO) so that your company stays ahead of your competitors at the top of the search engines. 8 Key Metrics Telemarketing Companies Need To Evaluate Performance. Your website should be professional, informative, and easy to use.
For a quantitative analysis of the generated impression, we use ROUGE (Recall-Oriented Understudy for Gisting Evaluation), the most commonly used metric for evaluating summarization. This metric compares an automatically produced summary against a reference or a set of references (human-produced) summary or translation.
Metaflow overview Metaflow was originally developed at Netflix to enable data scientists and ML engineers to build ML/AI systems quickly and deploy them on production-grade infrastructure. Through Metaflow and the deployment scripts provided in this post, you should be able to get started with Trainium with ease.
Amazon SageMaker Feature Store is a purpose-built feature management solution that helps data scientists and ML engineers securely store, discover, and share curated data used in training and prediction workflows. Amazon Athena is a serverless SQL query engine that natively supports Iceberg management procedures. AWS Glue Job setup.
Data scientists need to only provide a tabular dataset and select the target column to predict, and Autopilot automatically infers the problem type, performs data preprocessing and feature engineering, selects the algorithms and training mode, and explores different configurations to find the best ML model. script creates an Autopilot job.
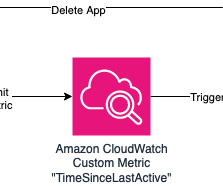
SageMaker Canvas now collects Amazon CloudWatch metrics that provide insight into app usage and idleness. This allows an administrator to define a solution that reads the idleness metric, compares it against a threshold, and defines a specific logic for automatic shutdown.
Before moving to full-scale production, BigBasket tried a pilot on SageMaker to evaluate performance, cost, and convenience metrics. Log model training metrics. Each worker then proceeds with the forward and backward pass defined in your training script on each GPU. Copy the final model to an S3 bucket.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content