This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
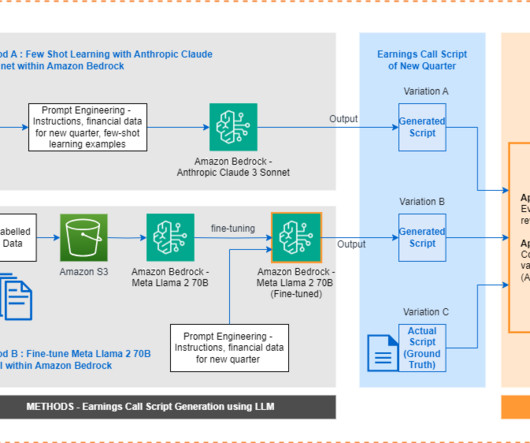
Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time. On the other hand, generative artificial intelligence (AI) models can learn these templates and produce coherent scripts when fed with quarterly financial data.
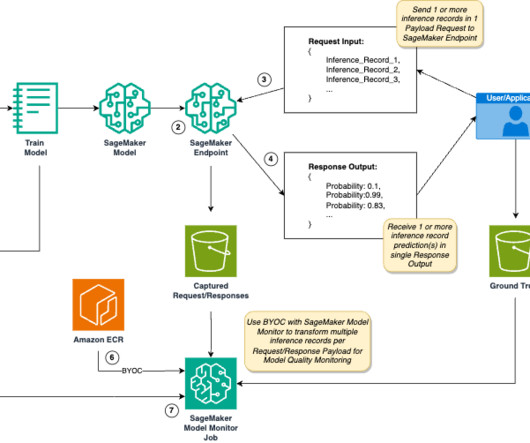
Examples include financial systems processing transaction data streams, recommendation engines processing user activity data, and computer vision models processing video frames. A preprocessor script is a capability of SageMaker Model Monitor to preprocess SageMaker endpoint data capture before creating metrics for model quality.
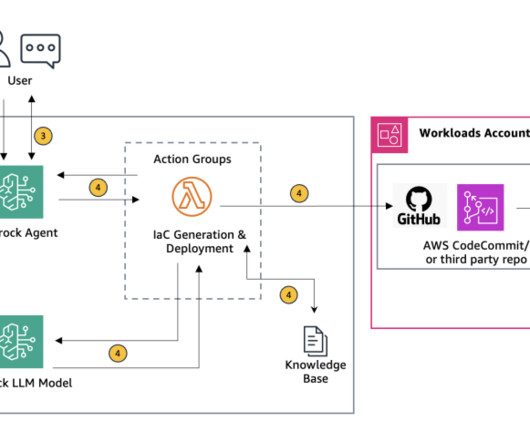
Amazon Bedrock empowers teams to generate Terraform and CloudFormation scripts that are custom fitted to organizational needs while seamlessly integrating compliance and security best practices. Traditionally, cloud engineers learning IaC would manually sift through documentation and best practices to write compliant IaC scripts.
Rather than relying on static scripts, Sophie autonomously decides how to engage. Check out how Sophie AI’s cognitive engine orchestrates smart interactions using a multi-layered approach to AI reasoning. Visual troubleshooting? Step-by-step voice support? Chat-based visual guidance? ” Curious how it works?
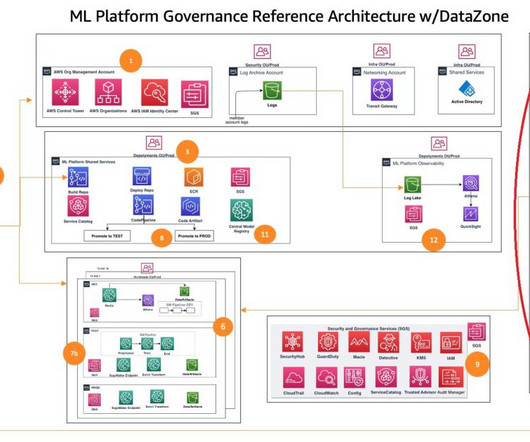
Challenges in data management Traditionally, managing and governing data across multiple systems involved tedious manual processes, custom scripts, and disconnected tools. As producers, data engineers in these accounts are responsible for creating, transforming, and managing data assets that will be cataloged and governed by Amazon DataZone.
Reasoning is the difference between a basic chatbot that follows a script and an AI-powered assistant or AI Agent that can anticipate your needs based on past interactions and take meaningful action. This typically involved both drawing on historical data and real-time insights.
script provided with the CRAG benchmark for accuracy evaluations. The script was enhanced to provide proper categorization of correct, incorrect, and missing responses. The default GPT-4o evaluation LLM in the evaluation script was replaced with the mixtral-8x7b-instruct-v0:1 model API.
from time import gmtime, strftime experiment_suffix = strftime('%d-%H-%M-%S', gmtime()) experiment_name = f"credit-risk-model-experiment-{experiment_suffix}" The processing script creates a new MLflow active experiment by calling the mlflow.set_experiment() method with the experiment name above. fit_transform(y). Madhubalasri B.
script to automatically copy the cdk configuration parameters to a configuration file by running the following command, still in the /cdk folder: /scripts/postdeploy.sh After the deployment is complete, you have two options. The preferred option is to use the provided postdeploy.sh
This requirement translates into time and effort investment of trained personnel, who could be support engineers or other technical staff, to review tens of thousands of support cases to arrive at an even distribution of 3,000 per category. Sonnet prediction accuracy through prompt engineering. We expect to release version 4.2.2
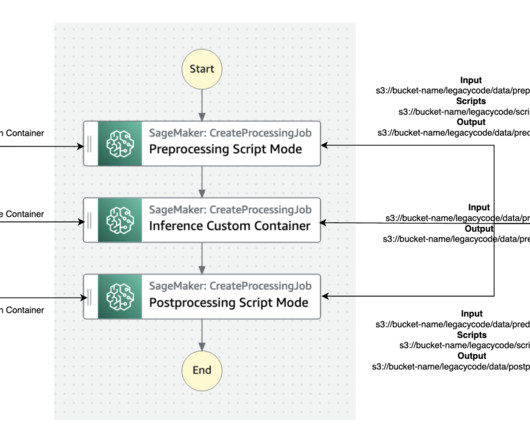
We demonstrate how two different personas, a data scientist and an MLOps engineer, can collaborate to lift and shift hundreds of legacy models. SageMaker runs the legacy script inside a processing container. We assume the involvement of two personas: a data scientist and an MLOps engineer.
Build your training script for the Hugging Face SageMaker estimator. script to use with Script Mode and pass hyperparameters for training. Thanks to our custom inference script hosted in a SageMaker endpoint, we can generate several summaries for this review with different text generation parameters. If we use an ml.g4dn.16xlarge
For early detection, implement custom testing scripts that run toxicity evaluations on new data and model outputs continuously. Integrating scheduled toxicity assessments and custom testing scripts into your development pipeline helps you continuously monitor and adjust model behavior.
Bill Dettering is the CEO and Founder of Zingtree , a SaaS solution for building interactive decision trees and agent scripts for contact centers (and many other industries). Interactive agent scripts from Zingtree solve this problem. Agents can also send feedback directly to script authors to further improve processes.
To address the problems associated with complex searches, this post describes in detail how you can achieve a search engine that is capable of searching for complex images by integrating Amazon Kendra and Amazon Rekognition. A Python script is used to aid in the process of uploading the datasets and generating the manifest file.
Older citizens, the unhealthy, and those in low-income areas have always been targets for social engineering. Now, so many more people are experiencing increased vulnerability, and hackers and social engineering cybercriminals are very aware. Second, inform customers of what you’ll never ask of them.
We also included a data exploration script to analyze the length of input and output tokens. About the authors Daniel Zagyva is a Senior ML Engineer at AWS Professional Services. For demonstration purposes, we select 3,000 samples and split them into train, validation, and test sets.
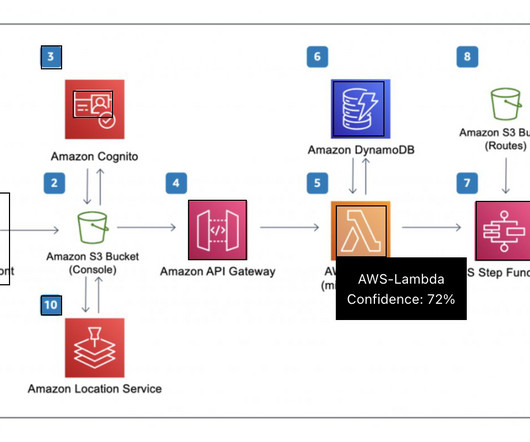
In the preceding architecture diagram, AWS WAF is integrated with Amazon API Gateway to filter incoming traffic, blocking unintended requests and protecting applications from threats like SQL injection, cross-site scripting (XSS), and DoS attacks. This can lead to privacy and confidentiality violations.
This enables data scientists to quickly build and iterate on ML models, and empowers ML engineers to run through continuous integration and continuous delivery (CI/CD) ML pipelines faster, decreasing time to production for models. You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices.
PrestoDB is an open source SQL query engine that is designed for fast analytic queries against data of any size from multiple sources. We use a preprocessing script to connect and query data from a PrestoDB instance using the user-specified SQL query in the config file. For more information on processing jobs, see Process data.
We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw. For example, to use the RedPajama dataset, use the following command: wget [link] python nemo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py
Agents for Amazon Bedrock automates the prompt engineering and orchestration of user-requested tasks. This solution uses Retrieval Augmented Generation (RAG) to ensure the generated scripts adhere to organizational needs and industry standards. A GitHub account with a repository to store the generated Terraform scripts.
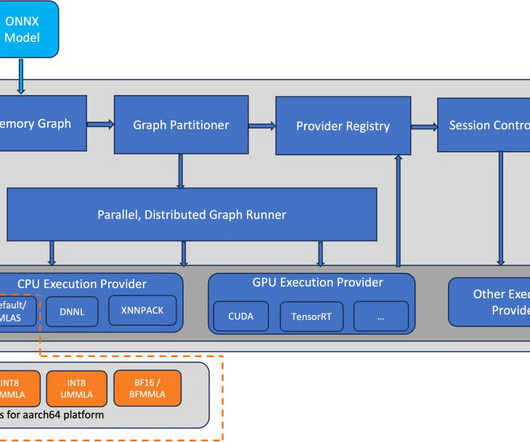
ONNX Runtime is the runtime engine used for model inference and training with ONNX. 1014-aws kernel) The ONNX Runtime repo provides inference benchmarking scripts for transformers-based language models. The scripts support a wide range of models, frameworks, and formats. Jammy with 6.5.0-1014-aws instead of 1.17.0 torch==2.2.1
For example, expenses related to sending an engineer to a customer site at British Telecom would have decreased. The cost of sending an engineer to a customer site was about £40 ($40). If the engineers brought the wrong part and went to see the customer, that’s a lot of money wasted.
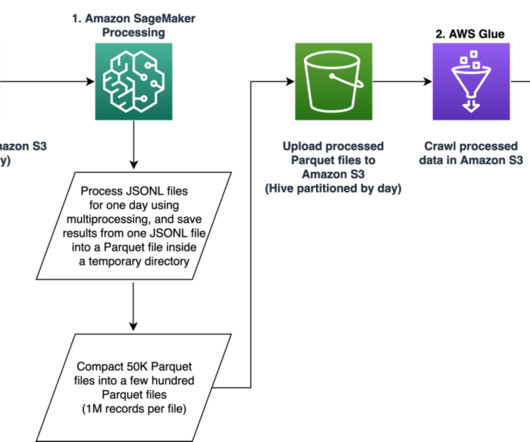
We recommend running similar scripts only on your own data sources after consulting with the team who manages them, or be sure to follow the terms of service for the sources that youre trying to fetch data from. A simple architectural representation of the steps involved is shown in the following figure.
With these updates to SMP’s APIs, you can now realize the performance benefits of SageMaker and the SMP library without overhauling your existing PyTorch FSDP training scripts. For more information on how to enable SMP with your existing PyTorch FSDP training scripts, refer to Get started with SMP.
SageMaker Studio allows data scientists, ML engineers, and data engineers to prepare data, build, train, and deploy ML models on one web interface. SageMaker is a comprehensive ML service enabling business analysts, data scientists, and MLOps engineers to build, train, and deploy ML models for any use case, regardless of ML expertise.
They had several skilled engineers and scientists building insightful models that improved the quality of risk analysis on their platform. SambaSafety’s data science team maintained several script-like artifacts as part of their development workflow. The challenges faced by this team were not related to data science.
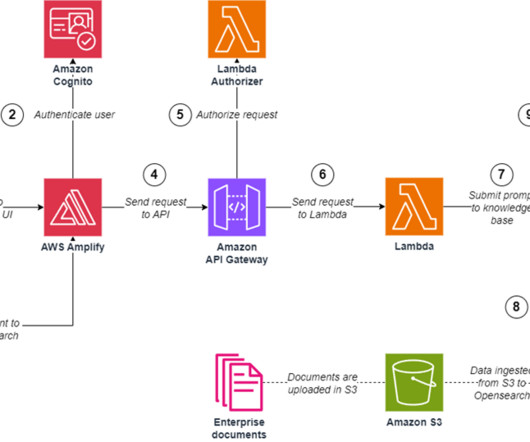
An Amazon OpenSearch Serverless vector engine to store enterprise data as vectors to perform semantic search. Amazon Bedrock retrieves relevant data from the vector store (using the vector engine for OpenSearch Serverless ) using hybrid search. You can also complete these steps by running the script cognito-create-testuser.sh
Solution overview To deploy your SageMaker HyperPod, you first prepare your environment by configuring your Amazon Virtual Private Cloud (Amazon VPC) network and security groups, deploying supporting services such as FSx for Lustre in your VPC, and publishing your Slurm lifecycle scripts to an S3 bucket. Choose Create role. Choose Save.
Real-Time Agent Guidance - Audio streaming software can feed recorded audio data right to a speech analytics engine which can tag and analyze the data to add meaning and structure. Likewise, the system can automatically provide script guidance to the agent to further mitigate potential problems.
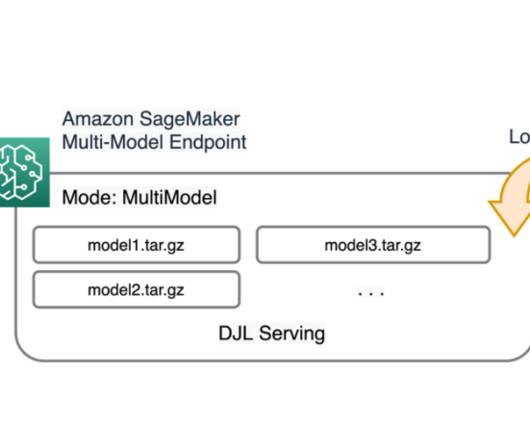
Integration with backend engines – Model servers have integrations with backend frameworks like DeepSpeed and FasterTransformer to partition large models and run highly optimized inference. Multi-engine support – DJL Serving can simultaneously host models using different frameworks (such as PyTorch and TensorFlow).
However, training or fine-tuning these large models for a custom use case requires a large amount of data and compute power, which adds to the overall engineering complexity of the ML stack. Most of the details will be abstracted by the automation scripts that we use to run the Llama2 example. Cluster with p4de.24xlarge
using open source or commercial-off-the-shelf search engines, then you’re probably familiar with the inherent accuracy challenges involved in getting relevant search results. You need your search engine to be smarter so it can rank documents based on matching the meaning or semantics of the content to the intention of the user’s query.
For instance, if a customer is searching for a “cotton crew neck t-shirt with a logo in front,” auto-tagging and attribute generation enable the search engine to pinpoint products that match not merely the broader “t-shirt” category, but also the specific attributes of “cotton” and “crew neck.” read()) Path("clip/serving.properties").open("w").write(
Lifecycle configurations are shell scripts triggered by Studio lifecycle events, such as starting a new Studio notebook. For Windows, use.cdk-venv/Scripts/activate.bat. For PowerShell, use.cdk-venv/Scripts/activate.ps1. About the Authors Cory Hairston is a Software Engineer with the Amazon ML Solutions Lab.
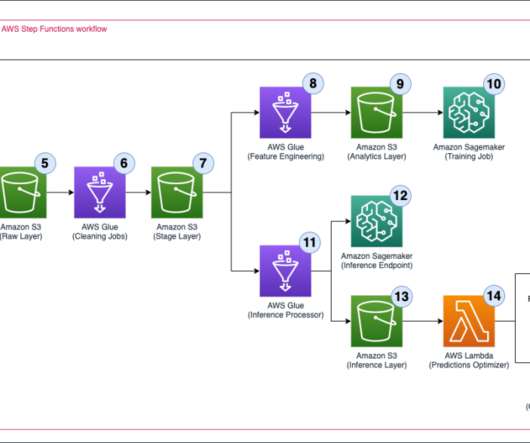
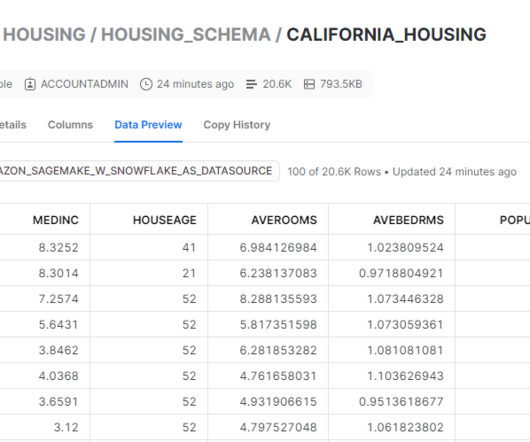
This is a guest post by Viktor Enrico Jeney, Senior Machine Learning Engineer at Adspert. The repricing ML model is a Scikit-Learn Random Forest implementation in SageMaker Script Mode, which is trained using data available in the S3 bucket (the analytics layer). This may be different to the partitioning used on the stage layer.
Before you can write scripts that use the Amazon Bedrock API, you need to install the appropriate version of the AWS SDK in your environment. For Python scripts, you can use the AWS SDK for Python (Boto3). For more information, refer to Prompt Engineering Guidelines. exclusive) to 10.0 Parse and decode the response.
By demonstrating the process of deploying fine-tuned models, we aim to empower data scientists, ML engineers, and application developers to harness the full potential of FMs while addressing unique application requirements. The scripts for fine-tuning and evaluation are available on the GitHub repository.
To use the TensorRT-LLM library, choose the TensorRT-LLM DLC from the available LMI DLCs and set engine=MPI among other settings such as option.model_id. To use SmoothQuant, set option.quantize=smoothquan t with engine = DeepSpeed in serving.properties. Qing Lan is a Software Development Engineer in AWS.
After the data is downloaded into the training instance, the custom training script performs data preparation tasks and then trains the ML model using the XGBoost Estimator. A Python script to connect to Secrets Manager to retrieve Snowflake credentials. All code for this post is available in the GitHub repo.
With your Python environment activated, run the following command: cdk synth Run the following command to deploy the AWS CDK: cdk deploy Run the following command to run the post-deployment script: python scripts/post_deployment_script.py CD into the scripts directory in the repository. script located in the GitHub repository.
This post is co-authored by Anatoly Khomenko, Machine Learning Engineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com. In line with this mission, Talent.com collaborated with AWS to develop a cutting-edge job recommendation engine driven by deep learning, aimed at assisting users in advancing their careers.
We can follow a simple three-step process to convert an experiment to a fully automated MLOps pipeline: Convert existing preprocessing, training, and evaluation code to command line scripts. Use the scripts created in step one as part of the processing and training steps. Integrate the pipeline into your CI/CD workflow.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content