This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal was to refine customer service scripts, provide coaching opportunities for agents, and improve call handling processes. Using data from sources like Amazon S3 and Snowflake, Intact builds comprehensive business intelligence dashboards showcasing key performance metrics such as periods of silence and call handle time.
Metrics, Measure, and Monitor – Make sure your metrics and associated goals are clear and concise while aligning with efficiency and effectiveness. Make each metric public and ensure everyone knows why that metric is measured. Interactive agent scripts from Zingtree solve this problem. Bill Dettering.
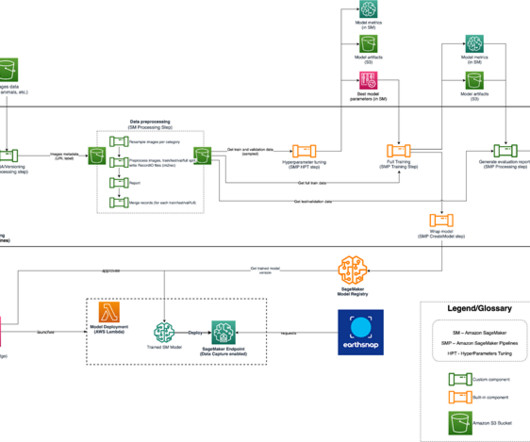
The DS uses SageMaker Training jobs to generate metrics captured by , selects a candidate model, and registers the model version inside the shared model group in their local model registry. Optionally, this model group can also be shared with their test and production accounts if local account access to model versions is needed.
Games24x7 is one of India’s most valuable multi-game platforms and entertains over 100 million gamers across various skill games. All the training and evaluation metrics were inspected manually from Amazon Simple Storage Service (Amazon S3). This helps in validating if our custom scripts will run on SageMaker instances.
The advanced AI model understands complex instructions with multiple objects and returns studio-quality images suitable for advertising , ecommerce, and entertainment. Before you can write scripts that use the Amazon Bedrock API, you need to install the appropriate version of the AWS SDK in your environment. exclusive) to 10.0
Evaluate model performance on the hold-out test data with various evaluation metrics. To run inference on this model, we first need to download the inference container ( deploy_image_uri ), inference script ( deploy_source_uri ), and pre-trained model ( base_model_uri ). Fine-tune the pre-trained model on a new custom dataset.
Trusted by the biggest names in entertainment, ZOO Digital delivers high-quality localization and media services at scale, including dubbing, subtitling, scripting, and compliance. git+[link] ffmpeg-python Create an inference script to load the models and run inference Next, we create a custom inference.py
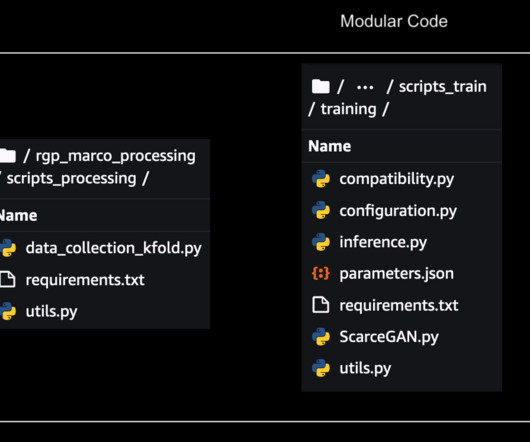
The ML components for data ingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers. This step produces an expanded report containing the model’s metrics.
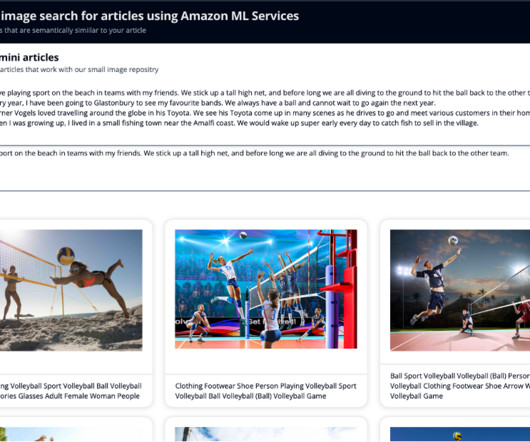
It produces high-quality embeddings and has one of the top performance metrics according to Hugging Face’s evaluation results. You then use Exact k-NN with scoring script so that you can search by two fields: celebrity names and the vector that captured the semantic information of the article.
To schedule the procedures, you set up an AWS Glue job using a Python shell script and create an AWS Glue job schedule. Next, you need to create a Python script to run the Iceberg procedures. You can find the sample script in GitHub. The script will execute the OPTIMIZE query using boto3. AWS Glue Job setup. Click Create.
Amp wanted a scalable data and analytics platform to enable easy access to data and perform machine leaning (ML) experiments for live audio transcription, content moderation, feature engineering, and a personal show recommendation service, and to inspect or measure business KPIs and metrics. This post is the first in a two-part series.
These metrics will help you assess performance, identify areas for improvement, and track progress over time. Consider the following key evaluation metrics: Response accuracy – This metric measures how your responses compare to your ground truth data. Task completion rate – This measures the success rate of the agent.
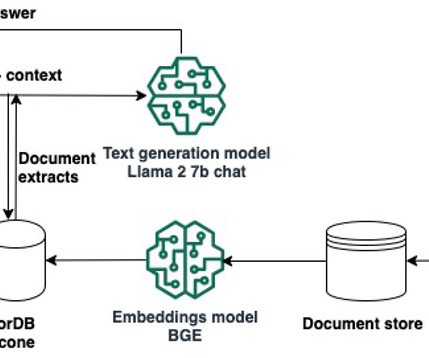
We use two AWS Media & Entertainment Blog posts as the sample external data, which we convert into embeddings with the BAAI/bge-small-en-v1.5 You can also set up lifecycle configuration scripts to automatically shut down resources when they are not used. embeddings.
Messaging is scripted – posts are scripted, approved by multiple levels and canned for use. Metrics focus on large numbers over meaningful ones – followers, total engagement define success with minimal further analysis. How can you make their lives easier, more informed, better entertained, etc.
ByteDance is a technology company that operates a range of content platforms to inform, educate, entertain, and inspire people across languages, cultures, and geographies. The Neuron team released this weight de-duplication feature in the Neuron libnrt library and also improved Neuron Tools for more precise metrics.
Modern AI technologies enhance productivity, automate routine work, and provide personalized experiences across industries – from retail to finance to entertainment. Another example of AI at work is seen in powerful call center scripting software solutions. Natural Language Generation creates human-like text in seconds.
Their use cases span various domains, from media entertainment to medical diagnostics and quality assurance in manufacturing. However, like other nascent technologies, obstacles remain in managing model intricacy, harmonizing diverse modalities, and formulating uniform evaluation metrics. box_threshold=0.5,
As drab and lifeless as this concept has known to become, it can be an extremely entertaining and interactive feature on your platform if used correctly, like shown in the example above. Developing a one-to-one relationship with the user by way of conversational communication (and not a scripted, one-word talk to boredom).
Review metrics before holiday to see how this can be improved. Entertain customers while they wait. This is why Disney dispatches characters to entertain people in ride queues, and doctors offer magazines in their waiting rooms. Free Download] Live Chat Scripts to Make Stellar Agents.
We simply tap into services to really meet our needs, whether those needs are we want some entertainment, we want to do some work, or we want to get from point A to point B. They’re not really after a movie; they want entertainment. And at Fender they asked: ‘What happens when we flip the script? It starts with the customer.
Some models may be trained on diverse text datasets like internet data, coding scripts, instructions, or human feedback. Training dataset – It’s also important to understand what kind of data the FM was trained on. Others may also be trained on multimodal datasets, like combinations of text and image data.
Consider inserting AWS Web Application Firewall (AWS WAF) in front to protect web applications and APIs from malicious bots , SQL injection attacks, cross-site scripting (XSS), and account takeovers with Fraud Control. He recharges through reading, traveling, food and wine, discovering new music, and advising early-stage startups.
The solution can integrate multiple LLMs, use customized evaluation metrics, and enable businesses to continuously monitor model performance. We also provide LLM-as-a-judge evaluation metrics using the newly released Amazon Nova models. The importance of each metric might vary depending on the specific application.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content