This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Our solution describes an AWS DeepRacer environment configuration using the AWS CDK to accelerate the journey of users experimenting with SageMaker log analysis and reinforcement learning on AWS for an AWS DeepRacer event. Choose Open Jupyter to start running the Python script for performing the log analysis.
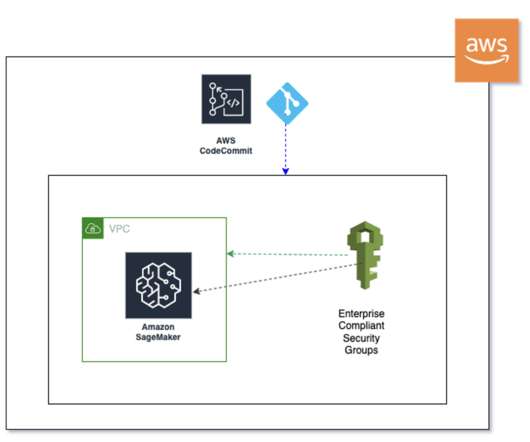
Continuous integration and continuous delivery (CI/CD) pipeline – Using the customer’s GitHub repository enabled code versioning and automated scripts to launch pipeline deployment whenever new versions of the code are committed. Implement group-based security for dashboard and analysis access control.
This notebook contains everything you need to run the transformations over our historical dataset and ingest the resulting features into Feature Store.This notebook uses Feature Store to create a feature group , runs your Data Wrangler flow on the entire dataset using a SageMaker processing job, and ingests the processed data to Feature Store.
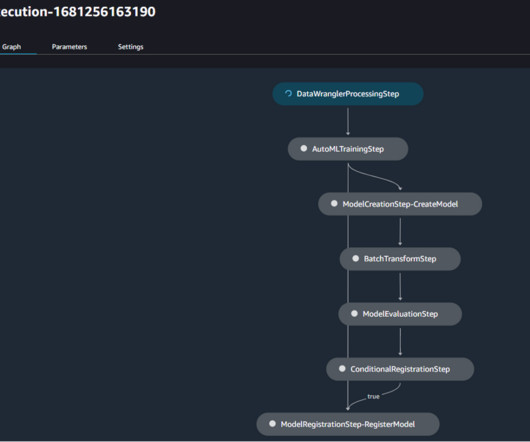
You can also add your own Python scripts and transformations to customize workflows. Model groups This tab lists groups of model versions that were created by pipeline runs in the project. You can choose the model group to access the latest version of the model. Choose the file browser icon view the path.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content