This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
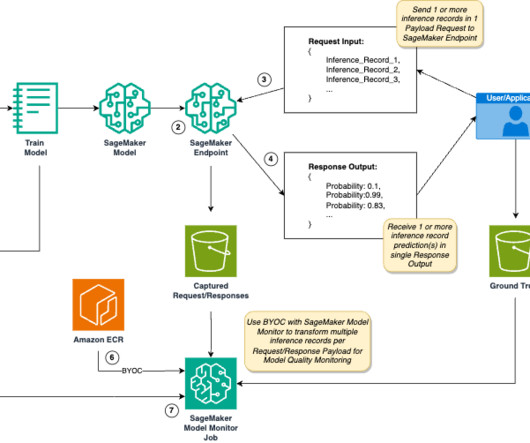
SageMaker Model Monitor adapts well to common AI/ML use cases and provides advanced capabilities given edge case requirements such as monitoring custom metrics, handling ground truth data, or processing inference data capture. For example, users can save the accuracy score of a model, or create custom metrics, to validate model quality.
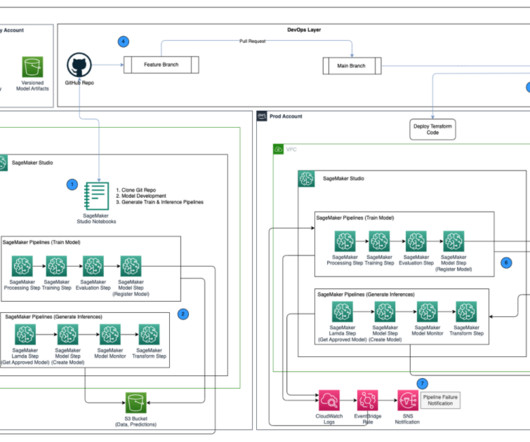
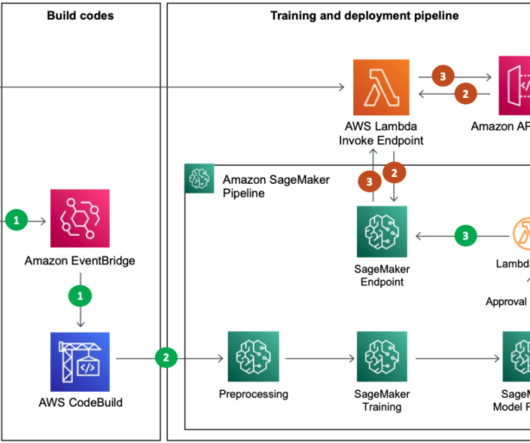
The following diagram depicts an architecture for centralizing model governance using AWS RAM for sharing models using a SageMaker Model Group , a core construct within SageMaker Model Registry where you register your model version. The MLE is notified to set up a model group for new model development.
Metrics, Measure, and Monitor – Make sure your metrics and associated goals are clear and concise while aligning with efficiency and effectiveness. Make each metric public and ensure everyone knows why that metric is measured. Rerouting the calls to the Campaign B agent group improves efficiency. Bill Dettering.
Ad Age) Here are 5 tips for marketing organizations looking to maximize their Discovery Commerce opportunity from Aubrie Richey, VP of media for TechStyle Fashion Group that brought us brands like Fabletics and Savage X Fenty. I have added my comment about each article and would like to hear what you think too.
For automatic model evaluation jobs, you can either use built-in datasets across three predefined metrics (accuracy, robustness, toxicity) or bring your own datasets. For early detection, implement custom testing scripts that run toxicity evaluations on new data and model outputs continuously.
But without numbers or metric data in hand, coming up with any new strategy would only consume your valuable time. For example, you need access to metrics like NPS, average response time and others like it to make sure you come up with relevant strategies that help you retain more customers. So, buckle up. 1: Customer Churn Rate. #2:
In essence, this structured interview process allows a group of candidates to work through tasks and assessments; it also gives those in charge of hiring the opportunity to select the best performers in the group and train them together to become new call center agents. Focus on the Metrics that Matter Most.
Encourage agents to cheer up callers with more flexible scripting. “A 2014 survey suggested that 69% of customers feel that their call center experience improves when the customer service agent doesn’t sound as though they are reading from a script. They are an easy way to track metrics and discover trends within your agents.
But without the contact center KPIs and metrics that managers use to measure the effectiveness of their operations, you’d never know for sure. We asked contact center industry influencers to share their insights into the changing role of KPIs and shine a light on new metrics to watch. KPIs matter. And they’re changing quickly.
Lead Segmentation Auto dialers can also break down leads into smaller groups to create targeted marketing campaigns. Dynamic Scripting Dynamic scripting customizes call scripts in real-time to support agent interactions. This allows you to manage your clients in one spot, eliminating the need for multiple programs.
In February 2022, Amazon Web Services added support for NVIDIA GPU metrics in Amazon CloudWatch , making it possible to push metrics from the Amazon CloudWatch Agent to Amazon CloudWatch and monitor your code for optimal GPU utilization. Then we explore two architectures. already installed. We will refer to it as “aws-do-eks shell”.
This post shows how Amazon SageMaker enables you to not only bring your own model algorithm using script mode, but also use the built-in HPO algorithm. You will learn how to easily output the evaluation metric of choice to Amazon CloudWatch , from which you can extract this metric to guide the automatic HPO algorithm.
You can then iterate on preprocessing, training, and evaluation scripts, as well as configuration choices. framework/createmodel/ – This directory contains a Python script that creates a SageMaker model object based on model artifacts from a SageMaker Pipelines training step. script is used by pipeline_service.py The model_unit.py
Cluster placement groups for optimized training – Each instance group is launched in a cluster placement group within the same network spine, in order to get the best inter-node latency and maximize bandwidth between nodes. Auto-resume functionality – This is one of the most valuable features of SageMaker HyperPod.
One of the challenges encountered by teams using Amazon Lookout for Metrics is quickly and efficiently connecting it to data visualization. The anomalies are presented individually on the Lookout for Metrics console, each with their own graph, making it difficult to view the set as a whole. Overview of solution.
“The anti-script doesn’t mean that you should wing it on every call… what anti-script means is, think about a physical paper script and an agent who is reading it off word for word… you’re taking the most powerful part of the human out of the human.” Share on Twitter. Share on Facebook.
If so, here’s how to go about it: Align KPIs with Culture Key performance indicators (KPIs) are metrics you can track to monitor how your call center (or business in general) is doing. The Northridge Group needs the contact information you provide to us to contact you about our products and services.
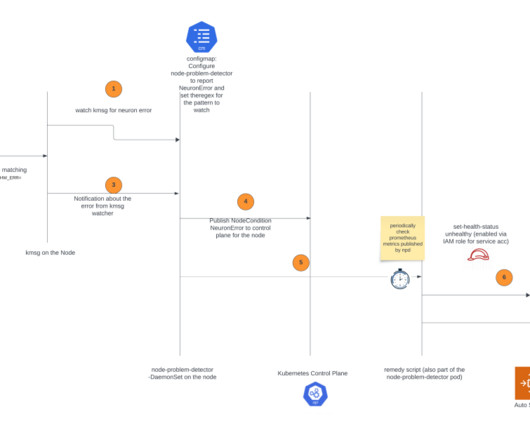
This solution is applicable if you’re using managed nodes or self-managed node groups (which use Amazon EC2 Auto Scaling groups ) on Amazon EKS. The node recovery agent is a separate component that periodically checks the Prometheus metrics exposed by the node problem detector. and public.ecr.aws. and public.ecr.aws.
Batch transform The batch transform pipeline consists of the following steps: The pipeline implements a data preparation step that retrieves data from a PrestoDB instance (using a data preprocessing script ) and stores the batch data in Amazon Simple Storage Service (Amazon S3). For more information on processing jobs, see Process data.
At Interaction Metrics, our approach to increasing customer retention is informed by the real problem with most customer feedback surveys: theyre impersonal, ineffective, and often ignored. Use real conversations, not scripts, to empathize genuinely: Genuine conversations build trust. But if its low, what can you do to improve it?
“A good outbound sales script contains a strong connecting statement. ” – Grace Sweeney, 5 Outbound Sales Scripts You Can Adjust on the Fly , Copper; Twitter: @copperinc. Keep metrics in mind and up to date. Segmenting your market into smaller groups also helps tailor your sales approach. Aim to connect.
When agents intentionally go off script, it’s because they are improvising to get a better call outcome and should be encouraged. In 2022, we published our findings on why agents intentionally go off their scripts. Why Agents Go Off Script. Figure 3: Why do agents go off script? Key Takeaways.
and make these variations available to a random group of website visitors who belong to the same demographics. The conversion rate (or any other predetermined metric) is measured and the variation that has the worse metric is discarded in favor of the better-performing variation.
Now more than ever, organizations need to actively manage the Average-Speed-of-Answer (ASA) metric. Eric Sachs is the CEO at Sachs Marketing Group. If that requires specific training for your staff or changes to call scripts to further show you are there for your customers, then that should absolutely be done. Eric Sachs.
Where discrete outcomes with labeled data exist, standard ML methods such as precision, recall, or other classic ML metrics can be used. These metrics provide high precision but are limited to specific use cases due to limited ground truth data. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
You can either have a manual approver or set up an automated approval workflow based on metrics checks in the aforementioned reports. We now explore this script in more detail. Values passed to arguments can be parsed using standard methods like argparse and will be used throughout the script.
The data preprocessing batches were created by writing a shell script to run Amazon EMR through AWS Command Line Interface (AWS CLI) commands, which we registered to Airflow to run at specific intervals. xlarge","Name":"Master Instance Group"},{"InstanceCount":2,"InstanceGroupType":"CORE","InstanceType":"r5.xlarge","Name":"Core
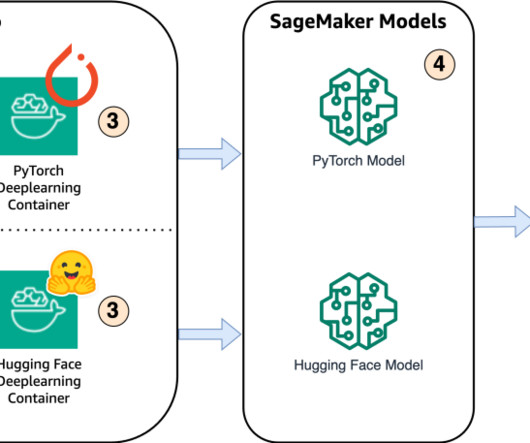
Next, we create custom inference scripts. Within these scripts, we define how the model should be loaded and specify the inference process. With the model artifacts, custom inference scripts and selected DLCs, we’ll create Amazon SageMaker models for PyTorch and Hugging Face respectively. In the custom inference.py
Inside the EKS cluster is a node group consisting of two or more trn1.32xlarge Trainium-based instances residing in the same Availability Zone. These images contain the Neuron SDK (excluding the Neuron driver, which runs directly on the Trn1 instances), PyTorch training script, and required dependencies. Lastly, the launchTemplate.id
As contact centers incorporate new technology and practices to keep up with shifting industry trends and competitors, call scripts remain one of the most widely used tools in the industry. So how useful is the classic script for agents alongside a shift to a remote or hybrid work environment? Figure 1: Script Usage By Work Environment.
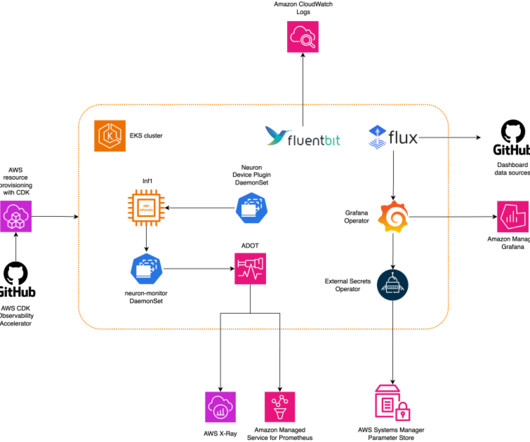
Most of the details will be abstracted by the automation scripts that we use to run the Llama2 example. A scripted walkthrough is available on GitHub for an out-of-the-box experience. Grafana dashboard Now that you understand how your system works on the pod and node level, it’s also important to look at metrics at the cluster level.
Metrics allow teams to understand workload behavior and optimize resource allocation and utilization, diagnose anomalies, and increase overall infrastructure efficiency. This solution deploys an Amazon EKS cluster with a node group that includes Inf1 instances. You should see a dashboard named Neuron / Monitor.
We have released an open-source project, AWS DevOps for EKS (aws-do-eks) , which provides a large collection of easy-to-use and configurable scripts and tools to provision EKS clusters and run distributed training jobs. script in the fsx folder. This sets up the correct policy and security group for accessing the file system.
The quick way to identify a CPU bottleneck is to monitor CPU and GPU utilization metrics for SageMaker training jobs in Amazon CloudWatch. You can access these views from the AWS Management Console within the training job page’s instance metrics hyperlink. Pick the relevant metrics and switch from 5-minute to 1-minute resolution.
It may sound complicated, but a fairly simple set of KPI metrics can help you measure your lead source ROI. The most important KPI metrics for monitoring your lead source ROI are: Cost per Acquisition. This metric assesses the quality of your lead lists. Sales script that needs improvement. Connection Rate.
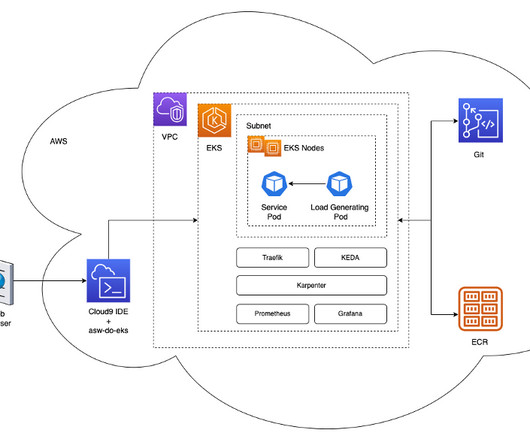
Solution overview In this section, we present a generic architecture that is similar to the one we use for our own workloads, which allows elastic deployment of models using efficient auto scaling based on custom metrics. The reverse proxy collects metrics about calls to the service and exposes them via a standard metrics API to Prometheus.
Finally, the labels are stored in a feature group in SageMaker Feature Store. We can follow a simple three-step process to convert an experiment to a fully automated MLOps pipeline: Convert existing preprocessing, training, and evaluation code to command line scripts. Let’s look at how to automate model building next!
Depending on the design of your feature groups and their scale, you can experience training query performance improvements of 10x to 100x by using this new capability. SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. Creating feature groups using Iceberg table format.
The digital nature of SaaS customer experience means that success outcomes are defined primarily in terms of digital, measurable key performance indicators, such as product usage metrics. Onboarding metrics, such as average time-to-value. Adoption metrics , such as license utilization.
Similarly, if you don’t explicitly specify a trial name, a pipeline run ID is used for the trial or run group name. If you want to perform different transformations on specific sub-groups in the data, you might have to run a different piece of code for every sub-group in the data. 1", instance_type="ml.m5.xlarge",
Include workshops and group activities as much as possible! Host training sessions regularly for all agents The first thing to have in your plan is a regular, formal, group training session for employees. Or, you might share a few metrics like FCR or abandon rate before and after your team uses Fonolo’s Voice Call-Backs!
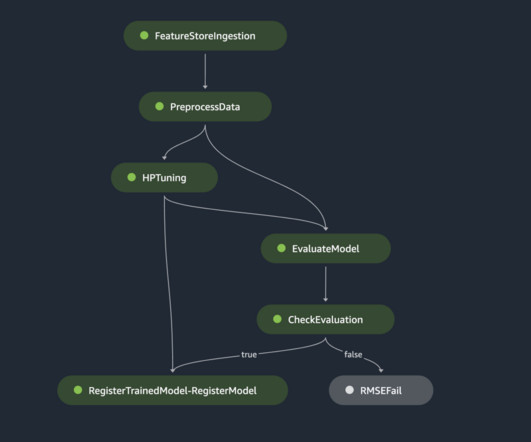
Each stage in the ML workflow is broken into discrete steps, with its own script that takes input and output parameters. Ingesting features into the feature store contains the following steps: Define a feature group and create the feature group in the feature store. See the following code: @ray.remote(num_cpus=0.5)
The company’s Data & Analytics team regularly receives client requests for unique reports, metrics, or insights, which require custom development. A lightweight approach was taken to quickly build the required technical and business catalogs using custom scripts. The following figure illustrates its code structure and workflow.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content