This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
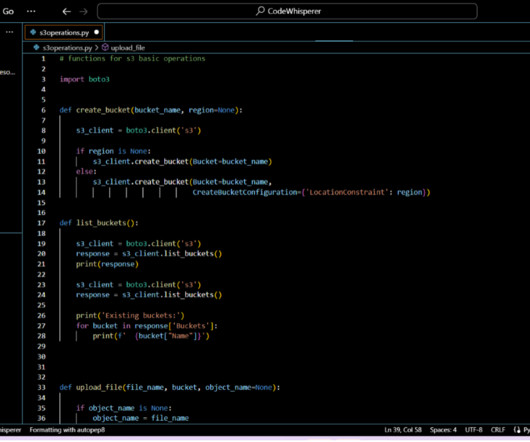
They were able to create a preprocessing data class just by typing “class to create preprocessing script for ML data.” Writing the preprocessing script took only a couple of minutes, and CodeWhisperer was able to generate entire code blocks. Writing boilerplate code Developers were able to use CodeWhisperer to complete prerequisites.
Our solution describes an AWS DeepRacer environment configuration using the AWS CDK to accelerate the journey of users experimenting with SageMaker log analysis and reinforcement learning on AWS for an AWS DeepRacer event. Choose Open Jupyter to start running the Python script for performing the log analysis.
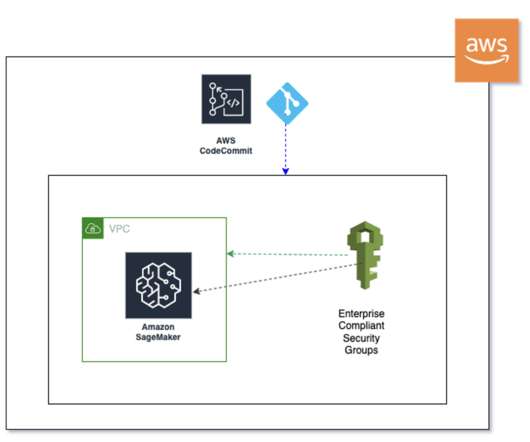
Continuous integration and continuous delivery (CI/CD) pipeline – Using the customer’s GitHub repository enabled code versioning and automated scripts to launch pipeline deployment whenever new versions of the code are committed. About the Authors Stephen Randolph is a Senior Partner Solutions Architect at Amazon Web Services (AWS).
Create a healthcare folder in the bucket you named via your AWS CDK script. He has over 8 years of industry experience from startups to large-scale enterprises, from IoT Research Engineer, Data Scientist, to Data & AI Architect. Then upload flow-healthcarediabetesunclean.csv to the folder and let the automation happen!
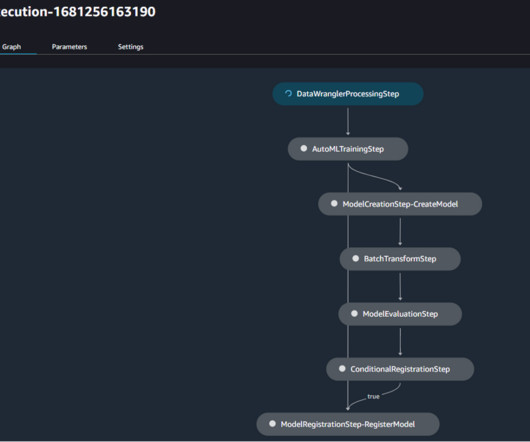
You can also add your own Python scripts and transformations to customize workflows. You can access the testing script from the local path of the code repository that we cloned earlier. We use Data Wrangler to perform preprocessing on the dataset before submitting the data to Autopilot. Choose the file browser icon view the path.
If you have a different format, you can potentially use Llama convert scripts or Mistral convert scripts to convert your model to a supported format. The fine-tuning scripts are based on the scripts provided by the Llama fine-tuning repository. from sagemaker.s3 3B model Now, we’ll fine-tune the Llama 3.2
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content